撩课-Python-每天5道面试题-第5天
2018-12-06 07:35:28来源:博客园 阅读 ()

一. 给定一个圆心和半径, 以及一个点坐标, 判定该点是否在圆内;
例如: 用户输入圆心: (1, 2) 半径: 2.5 测试点为(2, 2)
结果: 判定测试点是在圆内
思路:
- 结合勾股定理, 计算测试点距离圆心的距离test_distance;
- 比对test_distance 与半径的长短, 如果大于, 则不在圆内;
- 如果小于, 则在圆内
# 1. 获取测试案例数据 circle_center_str = input("请输入圆心坐标, 使用逗号分隔, 例如:1,2:") circle_radius_str = input("请输入圆的半径:") test_point_str = input("请输入测试点坐标, 使用逗号分隔, 例如:2,2:") # 2. 对数据进行处理, 转换成元组或者浮点数形式 circle_center = eval("({})".format(circle_center_str)) # 此步骤取巧, 你也可以拆解单独转化 circle_radius = float(circle_radius_str) test_point = eval("({})".format(test_point_str)) # 此步骤取巧, 你也可以拆解单独转化 # 3. 计算测试点距离圆心的距离 import math # 一般将模块导入, 放在最上面 test_distance = math.sqrt(math.pow(test_point[0] - circle_center[0], 2) + math.pow(test_point[1] - circle_center[1], 2)) # 4. 判定, 打印结果 result = "点在圆内" if test_distance <= circle_radius else "点在圆外" print(result)
二. 代码实现: 统计一篇文章中, 每个单词出现的个数
例如: "I like IT, do you like it?"
结果:
单词:i的个数为:1
单词:like的个数为:2
单词:it的个数为:2
单词:do的个数为:1
单词:you的个数为:1
注意: 不区分大小写
思路:
- 分割出文章中所有的单词
- 遍历单词列表, 通过字典记录每个单词个数{单词: 个数}
- 读取字典, 进行打印
# 0. 给定原始文章 content = "I like IT, do you like it?" # 1. 简单的通过正则, 分割文章为独立的单词 # 并对结果单词进行过滤, 单词进行小写, 压缩处理 import re word_list = re.split("[ ,.?!]", content) word_list = [word.strip(' ').lower() for word in word_list if len(word) > 0] # 2. 遍历单词列表, 通过字典进行统计 resut_dic = {} for word in word_list: if word in resut_dic.keys(): resut_dic[word] += 1 else: resut_dic[word] = 1 # print(resut_dic) # 3. 遍历字典键值对, 打印结果 for key, value in resut_dic.items(): print("单词:{}的个数为:{}".format(key, value))
三. 代码实现: 把一个列表,随机打乱;手动实现!
例如:num_list = [1, 2, 3, 4, 5]
结果可能是:[1, 2, 5, 4, 3] [5, 3, 4, 2, 1] 等等
每次执行都是随机结果;
思路:
- 获取列表长度
- 随机一个索引值
- 移除, 以及添加到另外一个列表中
import random num_list = [1, 2, 3, 4, 5] result = [] while len(num_list) > 0: idx = random.randint(0, len(num_list) - 1) result.append(num_list[idx]) del num_list[idx] print(result)
四. 用户输入一个字符串,判定是否为对称字符串;
例如: “abcxcba”,"abcxxcba"均为对称字符串;“abcb”则不是
思路:
方式1: 反转字符串, 对比即可
方式2: 循环遍历, 首尾字母进行比对
content = input("请输入一个测试字符串:") reverse_content = content[::-1] result = "是对称字符串" if content == reverse_content else "不是对称字符串" print(result)
五. 代码实现: 情报传递, 实现明文密文切换
切换规则为, 手机9宫格输入法和数字键的对应关系
例如: a 在九宫格输入法中的 2键位置的 索引为0的字符, 则可加密为: 20; 以此类推; 空格为 00
示例: "wo ai ni" ==> 9062002042006142
思路:
- 构造出明文到密文的破译表
- 通过比对破译表, 进行转换密文或者明文
# 0. 构造出密文明文对照字典 map_dic = { 2: "abc", 3: "def", 4: "ghi", 5: "jkl", 6: "mno", 7: "pqrs", 8: "tuv", 9: "wxyz", 0: " " } # 1. 为了提高执行效率, 可以采用, "空间换时间的策略" # 1.1 构造明文到密文的转换字典 # 1.2 构造密文到明文的转换字典 mingwen_to_miwen_dic = {} miwen_to_mingwen_dic = {} for key, value in map_dic.items(): for idx, char in enumerate(value): code = "{}{}".format(key, idx) mingwen_to_miwen_dic[char] = code miwen_to_mingwen_dic[code] = char print(mingwen_to_miwen_dic) print(miwen_to_mingwen_dic) # 2. 给定明文,进行加密 mingwen = "wo ai she hui sz" miwen = "" for char in mingwen: miwen += mingwen_to_miwen_dic[char] print(miwen) # 90620020420073413100418142007393 # 3. 给定密文, 解密 miwen = "90620020420073413100418142007393" mingwen = "" for idx in range(0, len(miwen), 2): code = miwen[idx: idx + 2] mingwen += miwen_to_mingwen_dic[code] print(mingwen)
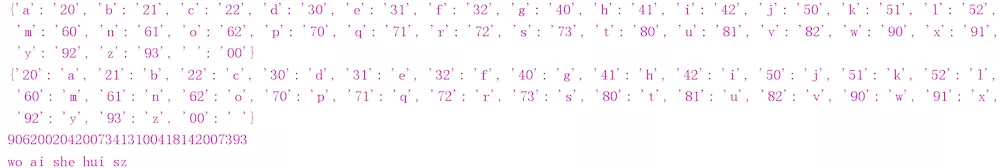
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

上一篇:2.Twisted学习
下一篇:虚拟运行环境Virtualenv
- 用Python监控你的女朋友/男朋友每天都在看哪些网站! 2019-03-13
- 作为python新手你应该知道的编程技巧! 2019-03-13
- 撩课-Python-每天5道面试题-第9天 2018-12-14
- 撩课-Python-每天5道面试题-第8天 2018-12-11
- 撩课-Python-每天5道面试题-第7天 2018-12-09
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
