python+selenium实现自动化百度搜索关键词
2019-07-24 09:28:32来源:博客园 阅读 ()

通过python配合爬虫接口利用selenium实现自动化打开chrome浏览器,进行百度关键词搜索。
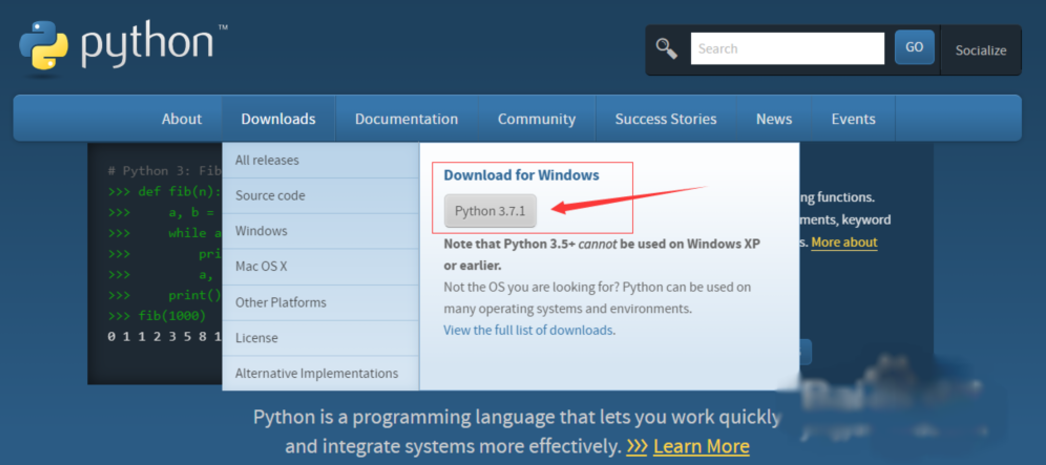
1、安装python3,访问官网选择对应的版本安装即可,最新版为3.7。
2、安装selenium库。
使用 pip install selenium 安装即可。
同时需要安装chromedriver,并放在python安装文件夹下,如下图所示。

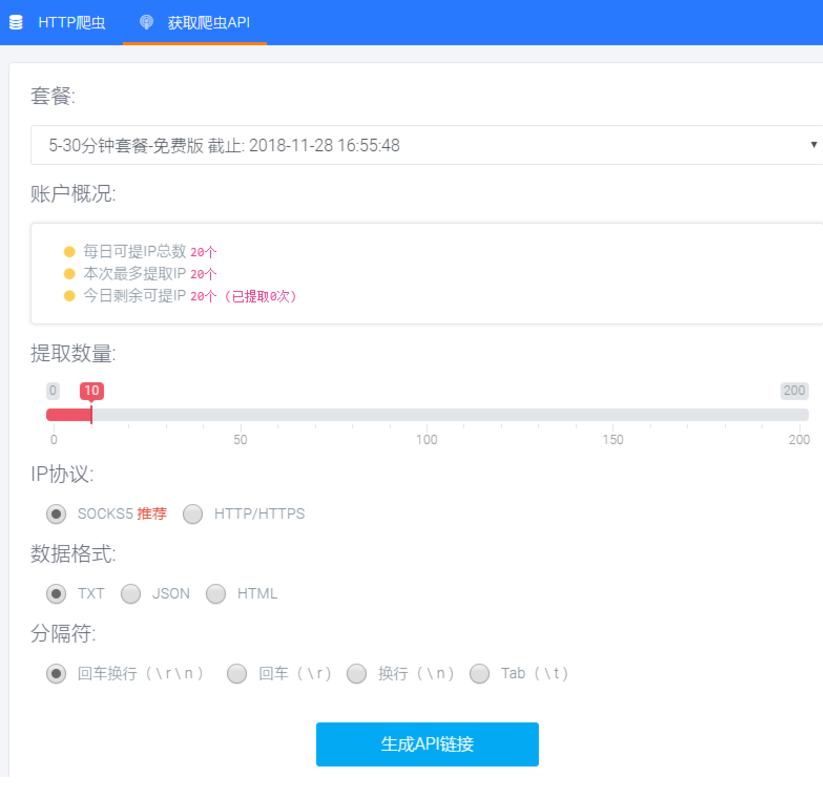
3、获取爬虫接口链接。
注册账号,点击爬虫代理,领取每日试用。
from selenium import webdriver import requests,time #自建IP池 def get_proxy(): r = requests.get('http://127.0.0.1:5555/random') return r.text import random FILE = './tuziip.txt' # 读取的txt文件路径 # 获取代理IP def proxy_ip(): ip_list = [] with open(FILE, 'r') as f: while True: line = f.readline() if not line: break ip_list.append(line.strip()) ip_port = random.choice(ip_list) return ip_port def bd(): chromeOptions = webdriver.ChromeOptions() # 设置代理 chromeOptions.add_argument("--proxy-server=http://"+proxy_ip()) # 一定要注意,=两边不能有空格,不能是这样--proxy-server = http://202.20.16.82:10152 browser = webdriver.Chrome(chrome_options = chromeOptions) # 查看本机ip,查看代理是否起作用 browser.get("https://www.baidu.com/") browser.find_element_by_id("kw").send_keys("ip") browser.find_element_by_id("su").click() time.sleep(2) browser.find_element_by_id("kw").clear() time.sleep(1) browser.find_element_by_id("kw").send_keys("百度") browser.find_element_by_id("su").click() time.sleep(2) browser.find_element_by_id("kw").clear() time.sleep(1) browser.find_element_by_id("kw").send_keys("百度") browser.find_element_by_id("su").click() time.sleep(2) browser.find_element_by_id("kw").clear() time.sleep(1) browser.close() # 退出,清除浏览器缓存 browser.quit() if __name__ == "__main__": while True: bd()
5、运行程序,如下图所示,可自动化搜索。

原文链接:https://www.cnblogs.com/Pythonmiss/p/11225517.html
如有疑问请与原作者联系
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

上一篇:文本分类问题相关原理知识
- python day2-爬虫实现github登录 2019-08-13
- python自动化测试之DDT数据驱动 2019-07-24
- python + pyinstaller 实现将python程序打包成exe文件直接运 2019-07-24
- Python socket编程 (2)--实现文件验证登入 2019-07-24
- python实现查找最长公共子序列 2019-07-24
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
