用ASP.NET Core 2.1 建立规范的 REST API -- 翻…
2018-06-22 07:58:41来源:未知 阅读 ()

本文所需的一些预备知识可以看这里: http://www.cnblogs.com/cgzl/p/9010978.html 和 http://www.cnblogs.com/cgzl/p/9019314.html
建立Richardson成熟度2级的POST、GET、PUT、PATCH、DELETE的RESTful API请看这里:https://www.cnblogs.com/cgzl/p/9047626.html 和 https://www.cnblogs.com/cgzl/p/9080960.html
本文需要的代码 (右键另存,把后缀改为zip):https://images2018.cnblogs.com/blog/986268/201806/986268-20180604151009219-514390264.jpg
本代码已经更新至ASP.NET Core 2.1. (从ASP.NET Core 2.0 迁移至 ASP.NET Core 2.1: https://docs.microsoft.com/en-us/aspnet/core/migration/20_21?view=aspnetcore-2.1)
本文主要介绍一些常见情况的实现,包括:集合更新、翻页、排序、过滤等等。但是仍然是Richardson成熟度顶多为2级的Web API,未达到RESTful API的标准和约束。
集合的更新操作

看这种更新集合的情况,原来数据库里中国存了4个城市(北平,上海,盛京,海参崴);而几个世纪后北平改名叫北京了,盛京改名为沈阳了,海参崴不属于中国了就删除了,威海从县成为市就算是新增,而上海保持不变。现在就是要对中国的城市进行整体性的更新操作,里面会包含:添加、删除、更新操作。看代码:

集合更新,我一共分了三步进行的操作:
1. 把数据库中存在的但是传进来的数据里没有的城市删掉
2. 把数据库中没有的而传进来的数据里有的数据进行添加操作,其实这里只判断id为0即可
3. 把数据库中原有和传进来的参数里也存在的数据条目进行更新。
然后保存即可。
先看一下原有的数据:
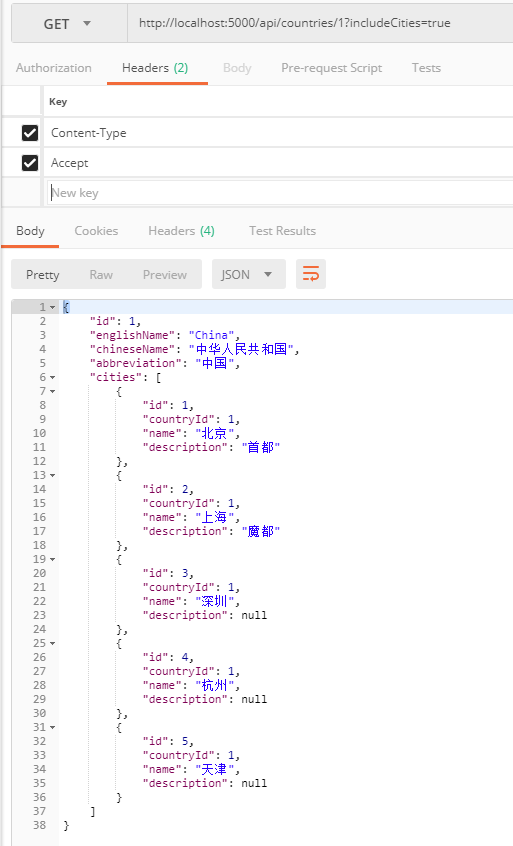
然后我们执行集合的更新:

执行之后,再次查询:
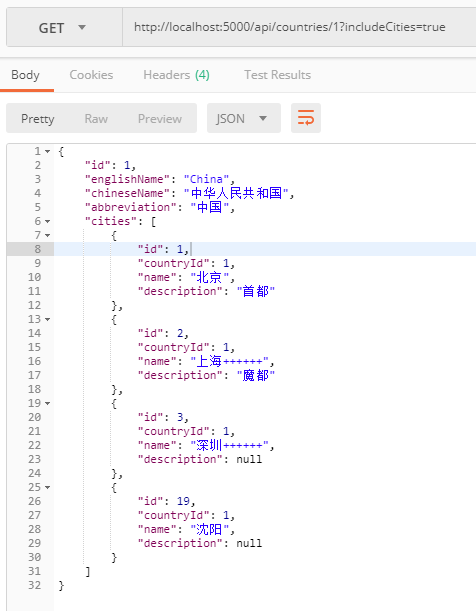
集合按预期更新了。
我相信大家肯定会写这段代码,或者有更简单的实现方式(请贴出来)。但这不是重点,我看到有人这样写,把上面那三步代码写在了AutoMapper的配置文件里:

首先,需要忽略Country的Cities属性的映射操作,然后把那部分代码写在AfterMap里面即可,这样在Action方法里面就简单了,可以使用Automapper了:

这只是一种可选的写法而已,不一定就必须放在AutoMapper的配置文件里。
翻页
翻页可以避免一些性能问题,不必一次性加载所有数据。所以最好默认就采用分页,而且每页的条目数量必须有限制,不能太大。
分页信息应该使用查询字符串(query stringg)传递参数。格式应该这样:
http://localhost:5000/api/country?pageIndex=12&pageSize=10
这里我喜欢使用pageIndex这个词,这也意味着页数是从0开始的;当然很多人喜欢用pageNumber等词,也就是说更喜欢页数从1开始,这个其实随意吧。
在ASP.NET Core里,我要使用Linq来动态组建一个查询的表达式(IQueryable<T>,可以创建表达式树),它是延迟执行的,直到各种条件都判断完了并组建出最终的查询表达式之后才去执行(查询数据库)。这个查询表达式只有在进行迭代的时候才会查询数据库。
触发迭代动作可以使用下面的方法:
- foreach 循环
- ToList(), ToArray(), ToDictionary() 以及相应的异步版本(ToXxxxAsync())
- 单项查询,例如 Average(), Count(), First(), FirstOrDefault(), SingleOrDefault()等等,以及相应的异步版本。
需要确保的是要在迭代发生之前,使用Skip()和Take()以及Where()。
下面我一点一点来写代码:

首先我们需要从参数(query string参数)传进来pageIndex和pageSize,还要赋默认值,以防止API的消费者没有设置pageIndex和pageSize;由于pageSize的值是由API的消费者来定的,所以应该在后端设定一个最大值,以免API的消费者设定一个很大的值。
由于所有的资源几乎都要使用翻页,所以我们最好使用一个公共类来封装这些翻页相关的信息:

(我暂时把这个类放在了Core项目里)。
这个公共类很简单,可以为pageIndex和pageSize设定默认值,也设置了一个每页的最多条目数是100;这里面还有一个OrderBy属性,默认值是“Id”,因为翻页必须要先排序,但目前这个OrderBy属性还没用上。
而针对具体的资源,我们可以再建立一个类继承于PaginationBase,这个类就是Country的参数类:

由于暂时还没有什么特别的参数,所以里面是空的。
下面我修改一下CountryRepository:

可以看到我组建了这个查询的表达式,并且直接出发了迭代动作,返回查询结果。
回到Action方法里:

我使用了这个参数类代替了之前的pageIndex和pageSize参数,因为ASP.NET Core足够智能,可以把这两个参数解析到这个类里面。
下面测试一下:

我就不进行多次测试了,这个是好用的。
如果你是用的是关系型数据库的话,应该可以在Log的输出媒介上看到打印出的SQL语句(但我这里使用的是内存数据库,所以看不到),如果使用关系型数据库还是看不到SQL语句的话,请配置一下:
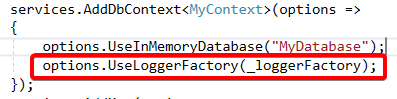
返回翻页的元数据
很显然只返回当前页的数据是不满足需求的,至少还需要返回总页数,总数等信息,还有可能需要返回前一页或者后一页的链接。但是如何把这些信息连同当页的数据一起返回给API消费者呢?
下面的做法是可以把这些数据都返回去的:
{ “data”: [{country1}, {country2}...], “metadata”: {"prev": "/api/...", ....} }
但是这样做的话就导致了响应的body不再符合Accept Header了(不是资源的JSON表述了),也就不是application/json了,而是一种新的media type。
所以如果返回这样的数据就违反了REST的规则了(尽管本文代码的Richardson成熟度最多也就是2级),它违反了自我描述的约束(请参考本系列的预备知识文章),API消费者不知道如何通过application/json这个设定的contety-type来解释响应数据了。
所以说翻页的元数据并不是资源表述的一部分。我们应该使用自定义的Header,例如“X-Pagination”来表述翻页元数据,这个名也是比较常用的。
首先,我创建一个类可以存放翻页的数据:

可以向上面这样做这个类:该类继承于List<T>,同时还包含PaginationBase作为属性,还可以判断是否有前一页和后一页。使用静态方法创建该类的实例。
这个静态方法也许会有一点点问题,这里没有使用异步方法,这样做是OK的;但是如果使用异步方法,例如source.CountAsync()和source.ToListAsync(),就会有一些问题,因为我需要修改CountryRepository的GetCountriesAsync方法的返回类型,改成上面这个类型,所以它的接口ICountryRepository也需要改;而它的接口是整个项目的核心并放在Core项目里,而整个项目的核心(合约)我个人认为应该是和具体的ORM无关的,但是这里依赖于EntityFrameworkCore了(ToListAsync())。所以我最后决定去掉这个静态方法,这样可能会导致多写一些代码;此外还添加HasPrevious和HasNext属性,判断是否有前一页和后一页:

(暂时放在Core项目里面了)。
然后修改CountryRepository:

然后在Action方法里,我们还需要生成前一页和后一页的URI,所以这里可以使用UrlHelper,需要在Startup的ConfigureServices方法里面注册:

然后回到Controller里面建立一个方法来生成URI:

在这里我还建立了一个枚举,PaginationResourceUriType。我还为PaginationBase添加了一个Clone()方法,目的是创建出一个属性值和它相同的另一个实例,因为这里有修改pageIndex属性这个操作;也许Clone不是最好的办法,直接new可能更合适。
下面就是修改Action方法了:
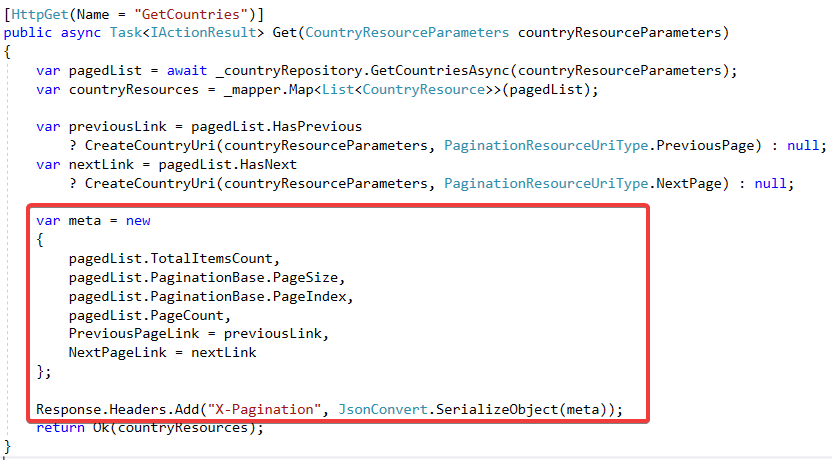
通过之前的方法分别创建出两个链接,然后把翻页相关的数据组成一个匿名类,使用JSON.NET将其串行化,并放到响应的自定义Header:“X-Pagination”里面。
而body部分还是资源的集合数据。
测试一下:
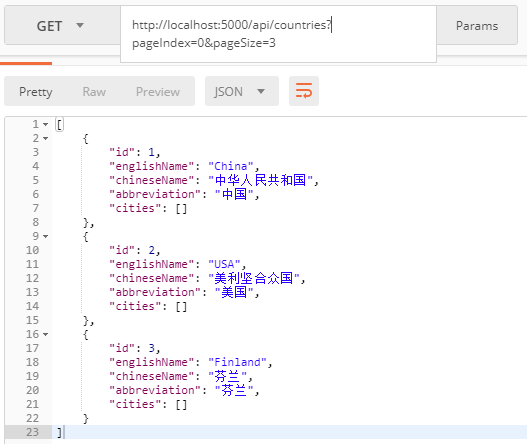
响应的body正常的返回来了,再看一下响应的Header:

可以看到自定义的X-Pagination Header了,然后我复制一下里面的NextPageLink链接,并发送该请求:


都没有问题。
这个Action目前的Richardson成熟度已经接近3级了(HATEOAS),但还不是。翻页现在是到这,下面要进行过滤并翻页。
过滤和搜索
过滤的意思就是对集合资源附加一些条件然后筛选出结果,它的URI是下面的形式:
http://localhost:5000/api/countries?englishName=China
所以需要在查询字符串里写上属性的名字和属性的值来表示要按这个属性的值来进行过滤,当然也可以写多个过滤的条件。
过滤的条件是应用于ResourceModel(或叫做Dto,ViewModel),例如CountryResource,而不应用于其它级别的Model,因为API消费者只知道ResourceModel,它不知道内部实现的细节,也就是不知道EntityModel的样子。
而搜索呢,是通过一个搜索关键字来模糊的筛选集合资源,可能会有多个属性针对这个关键字进行模糊筛选。
搜索的URI大致是下面的形式:
http://localhost/api/countries?searchTerm=hin
上面这个URI可以理解为针对Countries资源,凡是字符串类型的属性,它的值包含hin的都符合条件,就返回符合这个条件的结果。
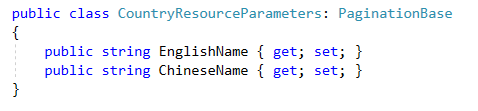
首先看一下过滤的实现。在Countries的GET Action方法里,我使用CountryResourceParameters类作为参数,所以要增加针对某个属性的过滤条件,只需扩展这个类即可,而增加的属性名要和ResourceModel里面的属性名一致:
然后是修改CountryRepository里面的方法:

首先要在执行分页动作之前附加过滤条件,query的类型必须是IQueryable<Country>才可以动态组建查询表达式,所以使用了AsQueryable()方法;然后分别判断两个条件并附加条件(注意大小写问题和两头空格的问题),最后再执行分页查询。
由于添加了参数,所以CreateUri的方法也需要改:
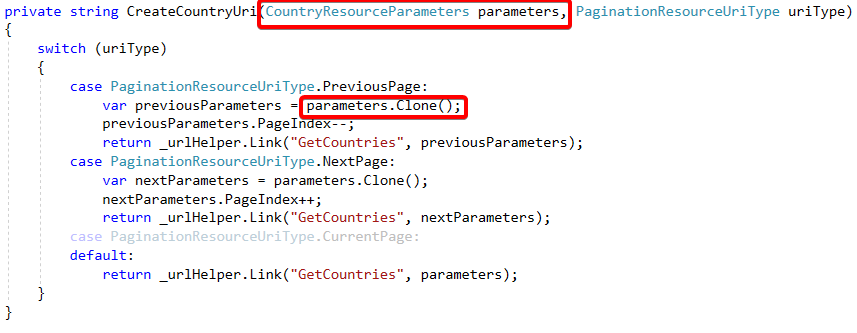
这个方法参数变成了CountryResourceParameters,而且Clone方法克隆出来的也是CountryResourceParameters类:

下面测试:
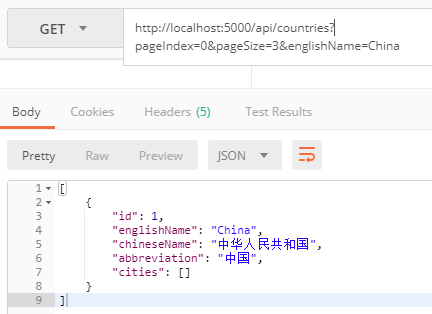
没有问题的,但是还要看看Header:
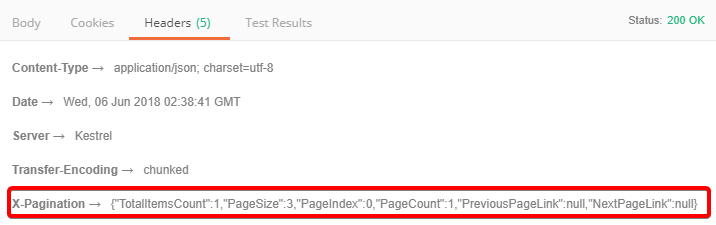
针对这个结果是OK的。
下面我做一些数据,使其拥有同样的EnglishName,然后测试:

OK,再看看Header:

使用NextLink再次发送请求, 结果是OK的,我就不贴图了。
但是你应该注意到,X-Pagination的属性名不符合camelCase命名规范,所以需要在转化成JSON的时候添加一些配置:

然后再测试一下:

属性的命名符合camelcase规范了,但是previousLink和nextLink里面的查询字符串的大小写依然不正确,所以我干脆去掉了Clone()方法,然后在CreateCountryUri的方法里直接new出来新链接的参数:

测试:

现在命名终于符合规范了。
排序
之前做的翻页都需要排序,暂时都是按照Id进行排序的。而实际上API消费者可能让资源按照资源的某个属性或多个属性进行正向或反向的排序。
我们先从最简单的例子开始,只考虑只按照某一个属性(针对的是资源的属性,例如CountryResource的EnglishName)进行排序,针对这个例子,我先使用比较笨的方法。
首先我假定,参数类里面的OrderBy属性如果以" desc" 结尾,例如:“EnglishName desc”,那么就是按照EnglishName倒序排列,而“EnglishName”就是正序排列。
只需在CountryRepository里面修改代码即可:

嗯,很笨重的代码。
先测试一下:

至少功能是OK的,再看一下倒序:

也OK,所以虽然代码很笨重,但是针对这种简单的情况是可以应付的。
下面我们对它进行第一次优化。像上面这样挨个属性的判断实在是太费劲了,所以我们来分析一下,OrderBy的值是字符串,而OrderBy()方法里面的lambda表达式的类型是Expression,具体的类型是Expression<Func<Country, object>>。这里简单讲一下,万一您不知道lambda表达式的话可以看一下。lambda表达式就是匿名的函数,它的类型是Func(可以赋值给Func类型的变量):

同时我们也可以把这个lambda表达式赋值给Expression:

而OrderBy()这个Linq方法接收的参数类型就是Expression<Func<Country, object>>。
使用Expression,我们可以构建Expression Tree;使用Expression Tree,可以表示一些逻辑。而在运行时,Linq的提供商将会解析这个Expression Tree,并把这些逻辑转化为SQL语句:

再看上面的排序条件判断,我们可以把OrderBy的字符串和Expression映射起来,就像Key-Value 键值对那样,这样做也许就会是代码稍微好看一些。所以你肯定会想到Dictionary<K, V>。
所以修改后的代码如下:

我相信你能看懂,我就不解释了,下面测试:

总之是好用的,我就不贴其他测试结果的图片了。
应该把上面这段代码提取出来封装成一个方法函数并泛型化,但是我暂时先不这样做。
经过第一次优化,使用Dictionary,代码简洁了许多,但是期间还是有手动把属性名字符串转化为Expression的动作。之所以这么写是因为OrderBy仅支持Expression的参数类型,如果支持字符串,那就完美了。
幸好有一个微软的库支持这种操作,它叫做System.Linq.Dynamic.Core(其作者是红衣教主啊):
我把它安装在了Infrastructure项目里供Repository使用。
再次修改排序那部分的代码:

注意这里OrderBy的命名空间是:System.Linq.Dynamic.Core。
经过第二次优化,代码已经很简洁了,但是还有很多待完善的地方,例如:
- Resource Model的一个属性可能会映射到Entity Model的多个属性上:Name 属性通常会映射成EntityModel的 FirstName 和 LastName属性
- Resource Model上的正序可能在Entity Model上就是倒序的:Age 升序,而Entity Model的BirthDate就是降序
- 需要支持多属性的排序:EnglishName desc, Id, ChineseName。
- 复用
第三次优化,要解决Model属性映射引起的问题。
也就是说要从ResourceModel的一个属性映射到Entity Model的一个或者多个属性上,而且它们之间的排列顺序可能是不同的,举一个极端的例子:
假设ResourceModel 有个属性叫做 Rank(排名) ,它所映射Entity Model的两个属性Result(成绩)和Weight(体重);假设这是举重比赛的Model,排名结果(Rank)是按照成绩(Result)从高到低排序的,但是如果多名选手的成绩相同,则体重轻的排名靠前。
也就是Rank asc -> Result desc, Weight asc。
用程序来说就是,一个字符串“Rank asc”要映射成一个集合,而集合元素的类型有两个属性:Entity Model的属性名和排序的方向。
所以先把集合里这种元素的类建立出来:

这里方向我是用的Revert这个单词,表示其方向是否与Resource Model的属性方向相反即可。
然后在做针对CountryResource的整套映射,不过首先我考虑建立一个抽象父类,里面可能有些公用的东西:

由于Id这个属性可能是每个相关的Model共有的,所以在这个父类里,我添加了Id属性的映射,Id是一对一的映射,排序方向相同。
然后我针对CountryResource,写一个派生于PropertyMapping的子类:
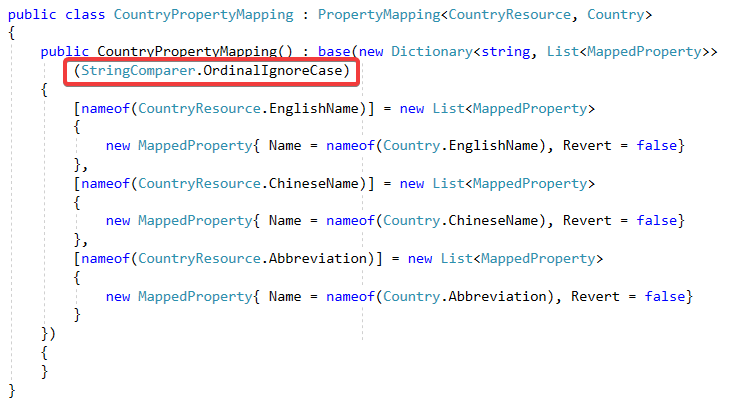
注意红框很重要,比较key的时候忽略大小写。
到这里,Resource和Entity Model之间映射的部分差不多做完了,接下来要考虑整个排序的问题,做这样一个扩展方法:

它应用于IQueryable,并把orderBy字符串和属性映射表传进来。
经过一些初步检验之后,把orderBy按“,”分解成字段属性的数组。然后去掉两边可能存在的空格,判断是否是倒序,提取出属性的名称。如果在映射表里面找不到该名称或者该名称对应的值是空,那就抛出异常。
然后先循环字段数组,然后内层循环该字段映射的属性集合。
最后通过DynamicLinq即可组建出所需的排序表达式。
使用DynamicLinq的OrderBy时要注意,排序条件必须反向附加,不信可以试试。
随后我们修改一下Repository:

就剩下一句话了,很简洁了。但是这里需要new一个CountryPropertyMapping类,这样做对单元测试就不友好了,也许把它放在一个容器里取出来用更合适?
那么就建立一个容器:

该容器的Register和Resolve分别用来注册和提取映射表。
下面还有个检查映射是否存在的方法,fields是一个或者多个字段属性组成的字符串,其格式如“EnglishName,ChineseName”;它检查是否能在映射配置表(MappingDictionary)找到相应的Key,如果找不到就验证失败。
这个容器在整个应用范围内也是个容器,所以需要在Startup里面注册,由于它的代码可能比较多(因为本身它也是个容器,还有很多注册内容用的代码),所以我单独写了个扩展方法:

该方法可以在Startup里面调用,从而注册到ASP.NET Core的服务容器里:

然后再次修改CountryRepository:

先注入了该容器服务,然后从该容器中按照映射两端的Model类型取出需要的映射表:

测试:

看起来是OK的,那我们针对排序,暂时先优化到这里。
排序的异常
还需要考虑到如果OrderBy里面的字段在映射表里面不存在的情况,所以我使用这个方法来进行判断:

我把这个方法放在了PropertyMappingContainer里,因为PropertyMappingContainer本身实际上就是一个服务,放在里还是比较合适的。
这里需要注意的是fileds里面的字段可能是这种形式的“EnglishName desc”,所以需要把空格和desc部分去掉。
随后在Action方法里调用即可:

测试:

应该是没问题的,我就不多测试了,以后要实行单元测试的。
资源塑形
如果某个资源的属性比较多,那么客户端的API消费者可能只需要一部分属性,这时就应该进行数据塑形,而且这样做有可能会提升性能。
数据塑形要考虑两种情况,集合资源和单个资源。
集合资源塑形
先考虑集合资源,首先我做一个扩展方法,把IEnumerable<T>可以转化为IEnumerable<dynamic>,这里要用到dynamic(ExpandoObject):

由于反射比较消耗资源,所以在这里,我一次性把需要的属性弄成PropertyInfo放到了一个集合里。如果fields是空的,说明需要所有属性,就把所有public和实例的property都放到集合里,否则,就把需要的属性放进去即可。
然后循环数据源,使用反射通过PropertyInfo获取该属性的值,最后组成一个ExpandoObject,再把这个ExpandoObject放到结果集合里面即可。
接下来修改参数类,因为这是个通用的东西,那就是为PaginationBase添加一个Fields属性吧:

最后修改Action方法:

测试:

好用的。但是返回的数据并不是camelcase的,这是因为JSON.net串行化的ContractResolver并不适用于Dictionary。下面来处理这个问题。
打开Startup,在services.AddMvc()后边添加:

这句话就是配置了JSON转化的ContractResolver。
在测试一下:

现在Ok了。
处理异常
但如果API消费者在Fields里面提供了不存在的属性,那么就应该返回Bad Request。
原理上我也许可以使用ProperyMappingContainer里面的验证方法,但是数据塑形并不使用映射表。而且目的不同,一个是排序一个是数据塑形,所以因为关注分离吧(SoC)。
我们要做的就是给定一个Fields和一个类型,需要判断Fields里面包含的字段属性在这个类型里面都存在,所以还是做一个Service比较好,可以注入使用。
看代码:
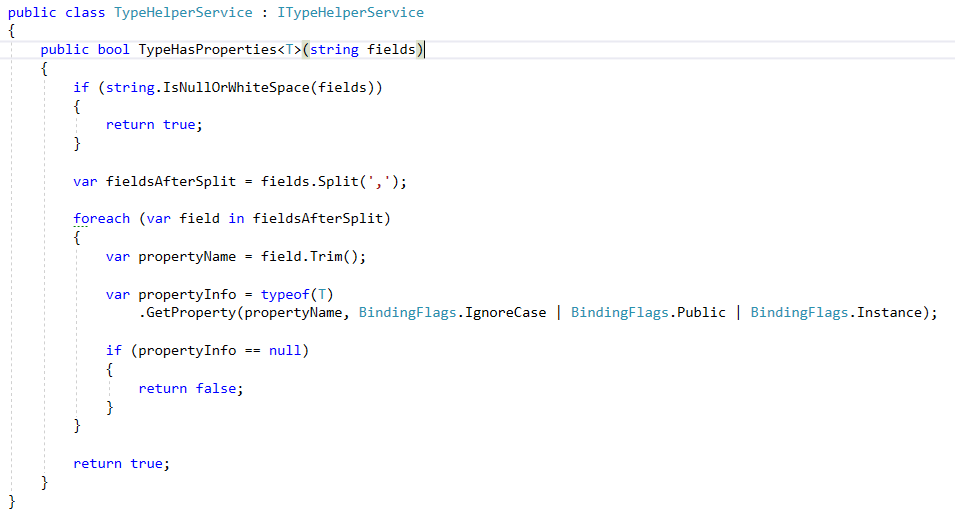
这个类比较简单不多讲了,别忘了在Startup里面注册。
然后在Controller里面注入并使用,别忘了还需要修改CreateCountryUri方法:

测试:

OK.
对单个资源塑形
这个跟集合的原理差不多,先建立一个扩展方法:

再修改Action即可:

测试:

是好用的,我就不多测试了。
针对数据塑形需要注意的是,尽量把Id带上,否则可能无法获取相关的链接了。
今天先写到这里,还有很多更深入一点的功能没有做,我就不做了。
到目前为止,这些Web API仍然称不上是RESTful的API,成熟度不够高,有些约束也没达到。下一篇文章会把升级这些API以便支持HATEOAS。
代码在这:https://github.com/solenovex/ASP.NET-Core-2.0-RESTful-API-Tutorial
项目有一些文件的拜访目录可能不对,暂时先不处理。
标签:
版权申明:本站文章部分自网络,如有侵权,请联系:west999com@outlook.com
特别注意:本站所有转载文章言论不代表本站观点,本站所提供的摄影照片,插画,设计作品,如需使用,请与原作者联系,版权归原作者所有

下一篇:Basic Auth
- asp.net源程序编译为dll文件并调用的实现过程 2020-03-29
- Asp.net MVC SignalR来做实时Web聊天实例代码 2020-03-29
- ASP.NET MVC中jQuery与angularjs混合应用传参并绑定数据 2020-03-29
- Asp.Net中WebForm的生命周期 2020-03-29
- ASP.NET使用Ajax返回Json对象的方法 2020-03-23
IDC资讯: 主机资讯 注册资讯 托管资讯 vps资讯 网站建设
网站运营: 建站经验 策划盈利 搜索优化 网站推广 免费资源
网络编程: Asp.Net编程 Asp编程 Php编程 Xml编程 Access Mssql Mysql 其它
服务器技术: Web服务器 Ftp服务器 Mail服务器 Dns服务器 安全防护
软件技巧: 其它软件 Word Excel Powerpoint Ghost Vista QQ空间 QQ FlashGet 迅雷
网页制作: FrontPages Dreamweaver Javascript css photoshop fireworks Flash
